无人区一码二码乱码的区别,无人区一码、二码和乱码有何区别?
在当今数字化时代,我们经常会遇到各种类型的编码和标识码。其中,无人区一码、二码和乱码是比较特殊的概念。将详细探讨无人区一码、二码和乱码之间的区别,帮助读者更好地理解这些概念。
在信息传递和数据处理过程中,编码和标识码起着至关重要的作用。对于一些不常见或特殊的编码情况,人们可能会感到困惑。无人区一码、二码和乱码就是其中的一部分,它们在特定的情境下出现,并且具有不同的特征和含义。通过深入研究这些区别,我们可以更好地应对各种编码问题,并确保信息的准确传递和处理。
无人区一码

无人区一码是指在特定编码系统中未被分配或未被定义的编码。这些编码通常不在常见的编码表中,因此在正常的编码操作中不会被使用。
无人区一码的出现可能有以下几种原因:
1. 编码系统的局限性:某些编码系统可能存在一定的限制,无法涵盖所有可能的情况。这可能导致一些编码被遗漏或未被定义。
2. 特定应用或领域的需求:在某些特定的应用或领域中,可能需要使用一些自定义的编码,但这些编码并未被纳入常见的编码标准中。
3. 历史原因:某些编码可能在过去被使用过,但随着时间的推移,它们可能不再被广泛使用或被新的编码所取代。
无人区一码的特点是它们没有明确的定义和规范,使用这些编码可能会导致兼容性问题或无法被其他系统正确识别。在处理无人区一码时,需要特别小心,确保使用的编码是合法和被支持的。
无人区二码
与无人区一码不同,无人区二码是指在特定编码系统中被错误地分配或定义的编码。这些编码虽然在编码表中有对应的位置,但它们的含义或使用方式与预期不符。
无人区二码的产生可能有以下原因:
1. 编码错误:在编码过程中可能会出现错误,导致编码被分配到错误的位置或具有错误的含义。
2. 不规范的使用:某些用户可能会不按照规范使用编码,将其用于不应该使用的情况,从而导致无人区二码的出现。
3. 编码表的不完善:编码表可能存在不完善的地方,导致一些编码的定义不明确或存在歧义。
无人区二码的存在可能会导致以下问题:
1. 数据混乱:使用无人区二码可能会导致数据的混乱和误解,因为其他系统可能无法正确解读这些编码。
2. 兼容性问题:与使用无人区一码类似,无人区二码可能会导致与其他系统的兼容性问题。
3. 安全风险:在某些情况下,无人区二码可能被恶意利用,导致安全漏洞或其他风险。
为了避免无人区二码的问题,我们应该遵循编码规范,并对编码进行仔细的检查和验证。
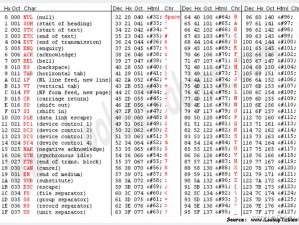
乱码是指在显示或传输过程中出现的无法识别或无意义的字符序列。这些字符可能是由于编码错误、数据损坏、传输中断等原因导致的。
乱码的出现会导致以下问题:
1. 信息无法解读:乱码使得用户无法理解显示的内容,从而无法获取所需的信息。
2. 系统错误:乱码可能会导致系统出现错误或异常,影响正常的操作。
3. 数据丢失或损坏:在传输过程中,乱码可能会导致数据的丢失或损坏,进一步加剧问题的严重性。
为了解决乱码问题,我们可以采取以下措施:
1. 检查编码:确保使用的编码与目标系统和数据源兼容,并进行正确的编码设置。
2. 数据校验和纠错:在传输数据时,可以使用校验和或纠错算法来检测和纠正可能出现的错误。
3. 数据备份和恢复:定期备份重要的数据,并建立数据恢复机制,以应对数据丢失或损坏的情况。
无人区一码、二码和乱码虽然在表现形式上有所不同,但它们都对信息的传递和处理带来了挑战。了解这些区别对于正确处理编码问题、确保数据的准确性和完整性至关重要。
在实际应用中,我们应该遵循编码规范,避免使用无人区一码和二码,并采取适当的措施来处理乱码问题。随着技术的不断发展和编码标准的不断完善,我们也应该保持对新的编码技术和规范的关注,以适应不断变化的需求。
通过对无人区一码、二码和乱码的深入研究,我们能够更好地应对编码相关的问题,提高信息处理的效率和质量,确保数字化世界的顺畅运行。
未来的研究方向可以包括进一步探索无人区编码的管理和利用方法,以及开发更智能的编码检测和纠正技术。针对不同领域和应用的编码特点进行深入研究,制定相应的最佳实践指南,也是未来的一个重要方向。
对无人区一码、二码和乱码的区别的理解是数字化时代中不可或缺的一部分,它对于保障信息的安全、准确和可靠传递具有重要意义。